
さて、今回のメモでは実際にニューラルネットワークモデルの構築を行いたいと思います。
学習するデータはアマゾンの星の数とそのレビュー内容で、文章の内容から製品に批判的か肯定的かを判定するものを作りました。
事前準備
ここでは学習データの用意と、ニューラルネットワーク以外のプログラムファイルを分けて作成したのでその準備を行います。
1. 学習データを用意する
今回「機械学習・深層学習による自然言語処理入門」という書籍を参考に勉強した内容を備忘録として記録しているのですが一つ問題が起きてしまいました。それは、書籍の中で使っているデータセットが現在では使えないことです、、、
そこで私はスクレイピングを用いてデータセットを用意しました。具体的な方法についてはほかの記事で書こうと思っていますので少々お待ちください。
今回用意したデータは下記のような感じです。
| Label | Content |
| 1 | 光学式センサーのブルーの光が出たりでなかったりして、使えないときが多く、使用を断念した。 |
| 1 | ホイールを回しても反応しない現象が頻繁に起こります。ストレス。 |
| 1 | 使用して9ヶ月程経過しました。電源を入れてもすぐ使えません。2〜3分待つと使えるようになるのですか、ポップアップで、電池が無いと表示されます。新しい電池を入れても1%と表示されます。OS的には100%です。 |
| 1 | 付属の電池が切れていました このようなことわ初めてです |
| 1 | スクロールホイールが軽すぎて、すぐクリックした状態になります。不具合なのか、そもそも軽いのか、どっちなんでしょう。もし、そもそも軽いのであれば、改良した方が使いやすいです。 |
「Label」にレビューの星の数、「Content」にレビューの本文が入っています。
事前準備2. 外部のPythonファイルを用意する
今回はmodel.py、utils.py、preprocessing.pyの3つの外部ファイルを利用しているのでまずは準備しましょう。
utils.py
このファイルは、CSVファイルからデータを読み込み、特定の条件でフィルタリングし、サンプリングするものです。
filter_by_ascii_rate関数:- テキストがASCII文字で構成されている割合を計算し、その割合が指定された閾値以下なら
Trueを返します。
- テキストがASCII文字で構成されている割合を計算し、その割合が指定された閾値以下なら
load_dataset関数:- CSVファイルを読み込みます。
- ラベルを整数に変換し、特定のラベルを二値ラベルに変換します。
- 日本語テキストのみを抽出します。
- データをシャッフルし、各ラベルごとに指定された数の行を抽出します。
- 最終的に、テキストとラベルの配列を返します。
このファイルは、機械学習モデルのトレーニングに適したデータセットを作成するために使われます。
import pandas as pd
import string
def filter_by_ascii_rate(text, threshold=0.9):
ascii_letters = set(string.printable)
if isinstance(text, str):
rate = sum(c in ascii_letters for c in text) / len(text)
return rate <= threshold
else:
return False
def load_dataset(filename, n=5722, state=6):
df = pd.read_csv(filename, sep=',')
df['Label'] = df['Label'].astype(int)
# Converts multi-class to binary-class.
mapping = {1: 0, 2: 0, 4: 1, 5: 1}
df = df[df['Label'] != 3]
df['Label'] = df['Label'].map(mapping)
# extracts Japanese texts.
is_jp = df['Content'].apply(filter_by_ascii_rate)
df = df[is_jp]
# sampling.
df = df.sample(frac=1, random_state=state) # shuffle
grouped = df.groupby('Label')
df = grouped.head(n=n)
return df['Content'].values, df['Label'].valuespreprocessing.py
tokenize関数- テキストを単語ごとに分割するための関数
clean_html 関数- HTMLからタグを取り除き、テキストだけを抽出。
from bs4 import BeautifulSoup
from janome.tokenizer import Tokenizer
t = Tokenizer(wakati=True)
def tokenize(text):
return t.tokenize(text)
def clean_html(html, strip=False):
soup = BeautifulSoup(html, 'html.parser')
text = soup.get_text(strip=strip)
return textmodel.py
create_model関数- kerasを用いたmodelを作成しreturnで返しています。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
def create_model(vocab_size, label_size, hidden_size=16):
model = Sequential()
model.add(Dense(hidden_size, activation='relu', input_shape=(vocab_size,)))
model.add(Dense(label_size, activation='softmax'))
return model実際にコードを書く
今回は教科書を参考にColaboratoryでも実行できるようにアレンジしました。
まずは下記のようなディレクトリ構成になっています。

1. 必要なモジュールのインポートを行う
janomeとbeautifulsoup4はcolabには標準装備ではないのでインストールする
!pip install janome beautifulsoup4また、colab環境でほかのPythonファイルをインポートしようとするとエラーが発生してしまうのでパスを通しておく
import sys
sys.path.append('/content/drive/MyDrive/自然言語処理編/chapter7')他に必要なモジュールをインポートする
import string
import pandas as pd
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from janome.tokenizer import Tokenizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, TensorBoard
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import load_model, Sequential
# 自分で作成したpythonファイルを読み込み
from model import create_model
from preprocess import clean_html, tokenize
from utils import load_dataset2. データの読み込み
csv_path = '/content/drive/MyDrive/自然言語処理編/chapter7/dataset.csv'
x, y = load_dataset(csv_path)3. HTMLのクリーニング(前処理)
x = [clean_html(text, strip=True) for text in x]x の各テキストからHTMLタグを削除し、クリーンなテキストに変換しています。
4. データの分割(前処理)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)データセット x とラベル y をトレーニングセットとテストセットに分割しています。test_size=0.2 はデータの20%をテストセットに割り当てることを意味し、random_state=42 は分割の再現性を確保するためのシード値です。
5. ベクトル化
vectorizer = CountVectorizer(tokenizer=tokenize)
x_train = vectorizer.fit_transform(x_train)
x_test = vectorizer.transform(x_test)
x_train = x_train.toarray()
x_test = x_test.toarray()CountVectorizer を使用してテキストデータをベクトル化しています。tokenizer=tokenize はカスタムトークナイザーを使用して単語をトークンに分割します。
fit_transform メソッドでトレーニングデータをベクトル化し、transform メソッドでテストデータを同じベクトル空間に変換します。
最後に、ベクトル化されたデータを配列に変換しています。
6. ハイパーパラメータに使うデータを設定
vocab_size = len(vectorizer.vocabulary_)
label_size = len(set(y_train))vocab_size はベクトル化された語彙のサイズ(ユニークな単語の数)を設定しています。
label_size はトレーニングデータに含まれるユニークなラベルの数を設定しています。
7. モデルの構築
model = create_model(vocab_size, label_size)
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)create_model関数を呼び出して、ニューラルネットワークモデルを作成しています。この関数には、語彙のサイズ (vocab_size) とラベルのサイズ (label_size ) が引数として渡されます。これにより、モデルの入力層と出力層のサイズが設定されます。
次にcompile メソッドを使用して、モデルをコンパイルしています。コンパイル時には以下のパラメータを指定しています。
optimizer='adam': モデルの最適化アルゴリズムとしてAdamを使用します。Adamは、学習率の調整を自動的に行う効率的な最適化アルゴリズムです。loss='sparse_categorical_crossentropy': 損失関数としてスパースカテゴリカルクロスエントロピーを使用します。これは、クラスラベルが整数で表現される分類問題に適しています。metrics=['accuracy']: モデルの評価指標として精度を使用します。これにより、モデルの性能を精度で評価することができます。
8. コールバック関数の準備
file_path = '/content/drive/MyDrive/自然言語処理編/chapter7/model.keras'
log_dir = '/content/drive/MyDrive/自然言語処理編/chapter7/logs'
callbacks = [
EarlyStopping(monitor='val_loss', patience=3),
ModelCheckpoint(
filepath=file_path,
save_best_only=True,
),
TensorBoard(log_dir=log_dir)
]コールバック関数としてEarlyStopping、ModelCheckpoint 、TensorBoard を使用することにしています。
9. モデルの学習を実施
epochs = 100
batch_size = 32
history = model.fit(
x_train, y_train,
validation_split=0.2,
epochs=epochs,
batch_size=batch_size,
callbacks=callbacks
)fit メゾットを利用して学習を行います。
10. 学習させたモデルの読み込み
model = load_model(file_path)先ほど学習させたモデルの読み込みを行っています。
新しいテキストに対する予測
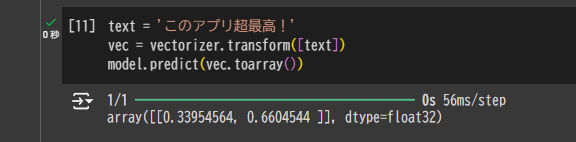
text = 'このアプリ超最高!'
vec = vectorizer.transform([text])
model.predict(vec.toarray())「このアプリ超最高!」という新しいレビューに対して、このモデルの予測を見てみましょう。
array([[0.33954564, 0.6604544 ]], dtype=float32)この出力結果はラベル[否定的(0ラベル), 肯定的(1ラベル)]に対応した確立を出しています。
つまり、否定的な可能性が約33%、肯定的な可能性が約66%と、このモデルが予測していることがわかります。
ニューラルネットワークを実際に作った感想
今回は二回に分けてニューラルネットワークの仕組から実装までを行ってみました。
データセットがないことや、Colab上で動かないトラブル等もありましたが最終的に問題解決ができて自分で実装できました。
次のメモではこのモデルの仕組みとか改善方法を知るためにどうしたらよいかなどの分析方法をまとめてみようと思います。
ちなみにデータの質による学習成果の差
このような英語のレビューが混じっているときの精度

すべての英語のテキストを日本語に翻訳してから学習させた結果↓
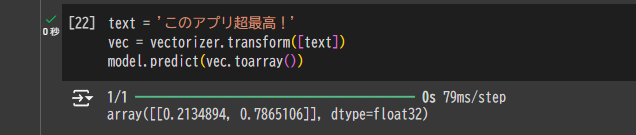
このように精度が上昇したことがわかります。
この記事は下記の書籍を参考にしています。

コメント