
今回のメモではKerasを用いてニューラルネットワークの実装を行うためにまず、モデルの構築方法を学んでいきます。
具体的にはアマゾンのレビューを用いて学習を行い、入力された文章が評価高めなのか、低めなのかを二値分類できるように学習させます。
モデルの定義を行おう
- Sequentialモデル:シンプルで直線的なモデルに適しています。
- FunctionalAPI:複雑な構造や複数の入力・出力を持つモデルに適しています。
Kerasではおもに上記の二つの方法でモデルを実装することができます。
Sequentialモデル
Sequentialモデルは、Kerasで最も基本的なモデルです。レイヤーを順番に積み重ねることで構築します。
まずインスタンスを作成します。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# モデルの初期化
model = Sequential()そして、このmodelに層を追加していきます。
# 入力層と隠れ層の追加
model.add(Dense(units=64, activation='relu', input_shape=(16,)))
# 出力層の追加
model.add(Dense(units=10, activation='softmax'))KerasのSequentialモデルに新しいDense(全結合)レイヤーを追加する部分です。各パラメータの意味を詳しく説明しますね。
model.add(Dense(...)): Sequentialモデルに新しいレイヤーを追加するメソッドです。Dense: 全結合層(Dense layer)を追加します。全結合層は、前の層のすべてのニューロンと接続される層です。units=64: このレイヤーの出力ニューロンの数を指定します。この場合、64個のニューロンが出力されます。activation='relu': 活性化関数をReLU(Rectified Linear Unit)に設定します。ReLUは、負の値を0にし、正の値はそのまま出力する関数です。ニューラルネットワークの学習を効率化するためによく使われます。input_shape=(16,): 入力データの形状を指定します。この場合、入力データは16次元のベクトルであることを意味します。これはモデルの最初のレイヤーにのみ必要な引数です。
一行目のコードは、16次元の入力を受け取り、64個のニューロンを持つ全結合層を追加し、ReLU活性化関数を適用することを意味します。
そして出力層のコードは10個のニューロンを持ち、活性化関数にsoftmax関数を適用するように設定してあります。
Functional API
Functional APIは、より複雑なモデルを構築するための柔軟な方法です。例えば、複数の入力や出力を持つモデルや、共有レイヤーを持つモデルなどを構築できます。以下は、Functional APIを使った例です。
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
# 入力層の定義
inputs = Input(shape=(16,))
# 隠れ層の定義
hide = Dense(units=64, activation='relu')(inputs)
# 出力層の定義
outputs = Dense(units=10, activation='softmax')(hide)
# モデルの定義
model = Model(inputs=[inputs], outputs=[outputs])Sequentialと違うところは、
# 隠れ層の定義
hide = Dense(units=64, activation='relu')(inputs)(inputs)のように関数の呼び出し形式で書くことができる点です。
また、inputs、outputsとModelの定義のところであるように、複数の入力、複数の出力に対応できるところにもあります。
また、モデルの定義はsummaryメゾットを使って確認することができます。
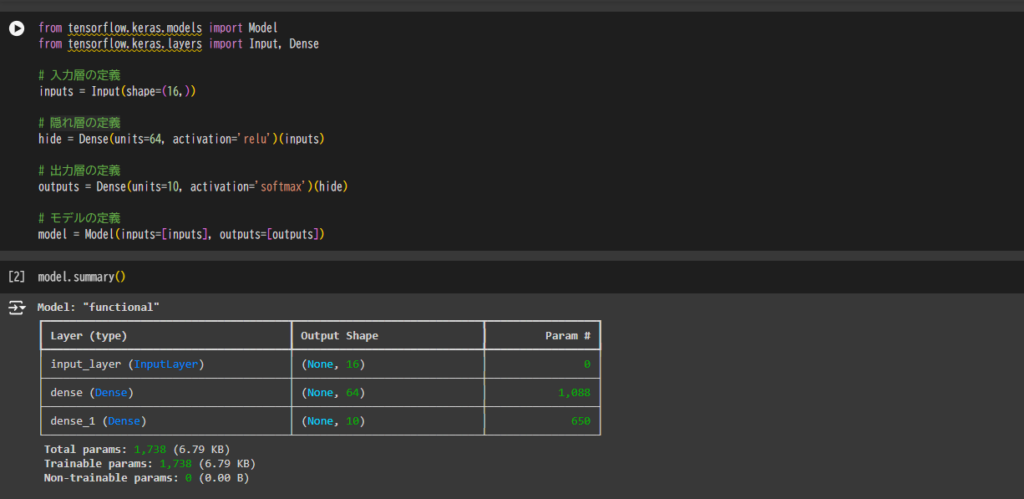
実際にモデルを構築しよう
さて、ここではSequentialモデルを利用して構築したいと思います。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
def build_model(vocab_size, label_size, hidden_size=32):
model = Sequential()
model.add(Dense(hidden_size, activation='relu', input_shape=(vocab_size,)))
model.add(Dense(label_size, activation='softmax'))
return modelこの関数 build_model の詳細を説明します:
- 引数:
vocab_size: 入力データの次元数(語彙のサイズ)。label_size: 出力データの次元数(ラベルのサイズ)。hidden_size: 隠れ層のユニット数(デフォルトは32)。
- モデルの構築:
Sequential(): モデルを順次に積み重ねるためのコンテナを作成します。Dense(hidden_size, activation='relu', input_shape=(vocab_size,)): 隠れ層を追加します。ユニット数はhidden_sizeで、活性化関数は ReLUです。入力の形状は(vocab_size,)です。Dense(label_size, activation='softmax'): 出力層を追加します。ユニット数はlabel_sizeで、活性化関数はソフトマックスです。これは分類問題において、各クラスの確率を出力するために使用されます。
最後に、出力層まで追加したmodelをreturnで返しています。
損失関数と最適化関数を指定しよう
上記で、モデルを定義しました。次はcompileメゾットを使用して学習に必要な損失関数と、最適化関数を指定します。compileメゾットではoptimizer、loss、metricsの3つのパラメータを指定します。
optimizer: モデルの重みを更新するためのアルゴリズムを指定します。例として、'adam'、'sgd'、'rmsprop'などがあります。loss: 損失関数を指定します。これはモデルがどれだけ誤差を出しているかを測定するためのものです。分類問題では'categorical_crossentropy'や'sparse_categorical_crossentropy'がよく使われます。metrics: モデルの評価指標を指定します。例えば、['accuracy']を指定すると、モデルの精度がトレーニング中に計算されます。他にも自分で定義した関数を評価にすることもできます。
lossとoptimizerを指定する例
model.compile(loss='sparse_categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])損失関数にsparse_categorical_crossentropy、最適化関数はsgd、評価指標はaccuracyを指定しています。
コールバック関数を使用
Kerasのコールバック関数は、モデルのトレーニング中に特定のイベントが発生したときに実行される関数です。これにより、トレーニングプロセスをカスタマイズしたり、監視したりすることができます。代表的なコールバック関数とその使用方法を紹介します。
1. EarlyStopping
EarlyStoppingは、モデルのトレーニングが過学習に陥るのを防ぐために使用されます。監視している指標(例えば検証損失)が一定期間改善しない場合、トレーニングを早期に終了します。これにより、無駄なエポックを避け、トレーニング時間を短縮できます。
- monitor: 監視する指標(例: ‘val_loss’, ‘val_accuracy’)。
- patience: 指標が改善しないエポック数の許容範囲。
- min_delta: 指標の改善と見なされる最小の変化量。
- mode: ‘min’(最小化)、’max’(最大化)、’auto’(自動判定)。
early_stopping = EarlyStopping(monitor='val_loss', patience=10, min_delta=0.001, mode='min')2. ModelCheckpoint
ModelCheckpointは、トレーニング中に最良のモデルを保存するために使用されます。特に長時間のトレーニングや複数のエポックを経る場合、最良のパフォーマンスを示したモデルを保存しておくことで、後でそのモデルを使用することができます。
- filepath: 保存先のファイルパス。
- monitor: 監視する指標。
- save_best_only: Trueの場合、最良のモデルのみを保存。
- mode: ‘min’、’max’、’auto’。
checkpoint = ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True, mode='min')3. TensorBoard
TensorBoardは、トレーニングの進行状況を可視化するために使用されます。トレーニング中の指標(損失や精度など)をリアルタイムで確認できるため、モデルのパフォーマンスを監視しやすくなります。また、ヒストグラムやグラフを通じてモデルの内部状態を視覚化することもできます。
- log_dir: ログファイルの保存先ディレクトリ。
- histogram_freq: ヒストグラムを計算する頻度(エポック数)。
- write_graph: Trueの場合、グラフをログに書き込む。
- write_images: Trueの場合、モデルの重みを画像として保存。
tensorboard = TensorBoard(log_dir='./logs', histogram_freq=1, write_graph=True, write_images=True)4. CSVLogger
CSVLoggerは、トレーニングの進行状況をCSVファイルに記録するために使用されます。これにより、トレーニングの履歴を後で分析したり、再現性のある実験を行ったりすることができます。
- filename: 保存するCSVファイルの名前。
- separator: CSVファイルの区切り文字(デフォルトは’,’)。
- append: Trueの場合、既存のファイルに追記。
csv_logger = CSVLogger('training.log', separator=',', append=False)5. LearningRateScheduler
LearningRateSchedulerは、トレーニング中に学習率を動的に変更するために使用されます。学習率はモデルのトレーニングにおいて重要なハイパーパラメータであり、適切に調整することでトレーニングの効率を向上させることができます。
- schedule: 学習率を計算する関数。引数としてエポック番号と現在の学習率を受け取る。
def scheduler(epoch, lr):
if epoch < 10:
return lr
else:
return lr * 0.1
lr_scheduler = LearningRateScheduler(scheduler)作成したモデルを学習させる
Kerasでよく用いられるのはfitメゾットとfit_generatorメゾットです。僕のメモではこの二つを使って学習させていこうと思います。
fitメゾットについて
Kerasのfitメソッドには、モデルの訓練をカスタマイズするための多くのパラメータがあります。以下に主なパラメータを説明します。
x: トレーニングデータの入力。NumPy配列、TensorFlowのテンソル、またはPandasのデータフレームが使用できます。y: トレーニングデータの出力。xと同じ形式で、ラベルデータを含みます。batch_size: 一度に処理するサンプル数。デフォルトは32です。epochs: トレーニングデータを繰り返し学習する回数。verbose: トレーニングの進行状況を表示する方法。0(表示なし)、1(進行バー)、2(エポックごとのメッセージ)から選択できます。validation_split: トレーニングデータの一部を検証データとして使用する割合。例えば、0.2と設定すると、20%のデータが検証に使用されます。validation_data: 検証データを直接指定する場合に使用します。タプル形式で(x_val, y_val)を渡します。shuffle: トレーニングデータを各エポックの前にシャッフルするかどうか。デフォルトはTrueです。class_weight: クラスごとの重みを指定する辞書。クラス不均衡を補正するために使用します。sample_weight: 各サンプルの重みを指定する配列。サンプルごとの重要度を調整できます。callbacks: トレーニング中に特定のイベントに応じて実行される関数のリスト。例えば、早期終了やモデルのチェックポイント保存など。
これらのパラメータを適切に設定することで、モデルのトレーニングを効率的かつ効果的に行うことができます。
fit_generatorメゾットについて
Kerasのfit_generatorメソッドには、モデルのトレーニングをカスタマイズするための多くのパラメータがあります。以下に主なパラメータを説明します。
generator: バッチごとにデータを生成するジェネレータ。これは、__getitem__と__len__メソッドを持つPythonのジェネレータオブジェクトである必要があります。steps_per_epoch: 1エポックあたりのステップ数。通常、トレーニングデータのサンプル数をバッチサイズで割った値です。epochs: トレーニングデータを繰り返し学習する回数。verbose: トレーニングの進行状況を表示する方法。0(表示なし)、1(進行バー)、2(エポックごとのメッセージ)から選択できます。callbacks: トレーニング中に特定のイベントに応じて実行される関数のリスト。例えば、早期終了やモデルのチェックポイント保存など。validation_data: 検証データを直接指定する場合に使用します。ジェネレータオブジェクトまたはタプル形式で(x_val, y_val)を渡します。validation_steps: 1エポックあたりの検証ステップ数。通常、検証データのサンプル数をバッチサイズで割った値です。class_weight: クラスごとの重みを指定する辞書。クラス不均衡を補正するために使用します。sample_weight: 各サンプルの重みを指定する配列。サンプルごとの重要度を調整できます。max_queue_size: ジェネレータからのデータを待機させるキューの最大サイズ。デフォルトは10です。workers: データ生成に使用するスレッド数。デフォルトは1です。use_multiprocessing: マルチプロセッシングを使用するかどうか。デフォルトはFalseです。
これらのパラメータを適切に設定することで、モデルのトレーニングを効率的かつ効果的に行うことができます。
fitメゾットとfit_generatorメゾットの違いについて
- メモリ使用量:
fitはデータ全体をメモリに読み込むため、メモリ使用量が多くなります。一方、fit_generatorはバッチごとにデータを生成するため、メモリ使用量が少なくて済みます。 - データの前処理:
fit_generatorはバッチごとにデータを生成するため、リアルタイムでのデータ前処理やデータ拡張が容易です。 - 適用シナリオ: 小規模データセットには
fit、大規模データセットにはfit_generatorが適しています。
学習させたモデルを使って予測を出す
学習したモデルを使って新しいデータに対する予測を出す際にはpredictメゾットを使用します。
具体的な使い方は学習の時のデータと同じ形式でデータを与えることで使用できます。
predict(x)モデルの保存と読み込み
モデルを保存するということは学習した重みとアーキテクチャを保存するということです。アーキテクチャとは、ニューラルネットワークの構造のことを指しており、各層のニューロンの数や層同士の結合のパターン、活性化関数の情報などのことを示しています。
この重みとアーキテクチャを保存するためにはsaveメゾットを使用します。
model.save('model.keras')保存したモデルを呼び出すにはload_modelを使うことで呼び出せます。
from tensorflow.keras.models import load_model
model = load_model('model.keras')モデルの構築と保存を学んだ
今回の記事でモデルの構築の仕方から保存の仕方までを学びました。
次回はこれらの知識を生かして実際のモデルを構築し、予測を行えるところまでしようと思います。
この記事は下記の書籍を参考にしています。

コメント