
ここまでで、単語を機械に認識させる方法について学んできましたが、それ単体ではまだ実用的な技術には及びません。ここからはもっと実用的なテキスト分類の技術について学習していきます。自然言語処理(NLP)におけるテキスト分類は、特定のテキストをあらかじめ定義されたカテゴリやラベルに分類するタスクです。これは、ニュース記事のトピック分類、スパムメールの検出、感情分析など、さまざまな応用があります。
リカレントニューラルネットワーク(RNN)
今まで学習してきたニューラルネットワークでは単語を常に固定長のベクトルに変換して入力していました。しかし、RNNでは可変長の入力を扱えるようになるうえ、入力の順番なども考慮できるため、文章の中の次の単語を予測するなどのタスクもこなせるようになります。
「明日の天気は」 → 「晴れ」
→ 「曇り」
→ 「雨」
・・・次の単語を予測できる
RNNの基本構造
RNNは、入力層、隠れ層、出力層の3層から構成されています。特徴的なのは、隠れ層が「再帰的」な構造を持っている点です。これは、前のタイムステップの出力を次のタイムステップの入力として利用することを意味します。
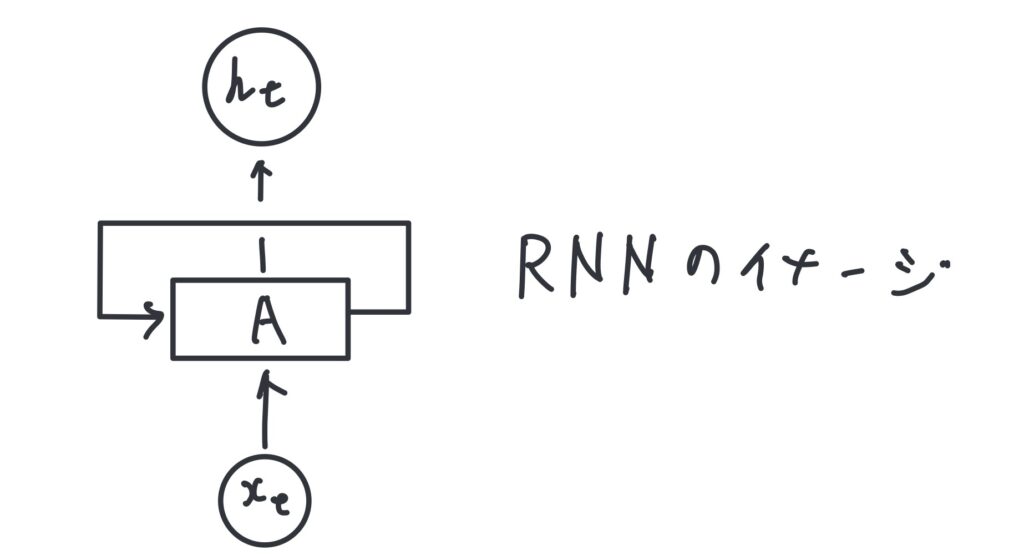
動作の流れ
- 入力データ (x_t) が時刻 (t) に入力されます。
- 隠れ層では、前の時刻 (t-1) の隠れ層の状態 (h_{t-1}) と現在の入力 (x_t) を組み合わせて、新しい隠れ層の状態 (h_t) を計算します。
- 出力層で、隠れ層の状態 (h_t) から出力 (y_t) が生成されます。
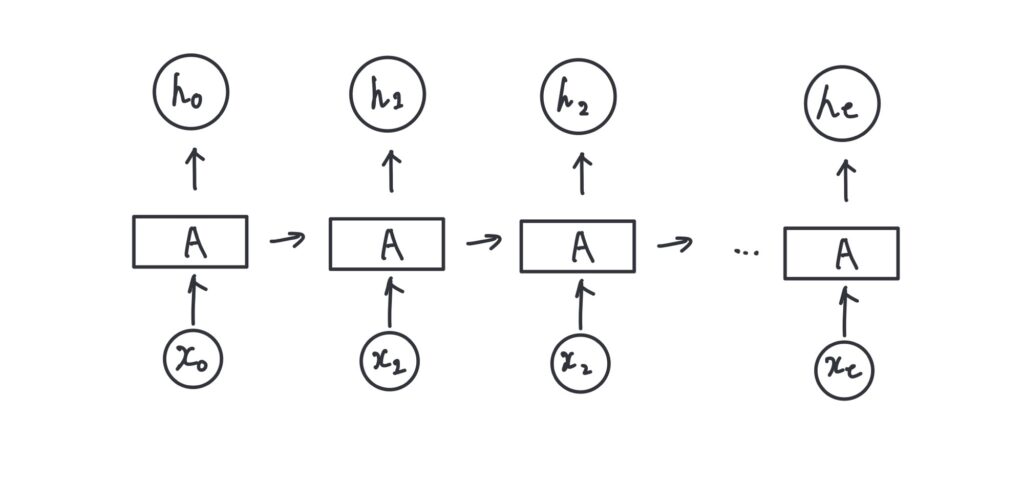
このようにして、RNNは過去の情報を保持しながら新しい入力に対して適応的な反応を行うことができます。
隠れ層の状態の更新の数式
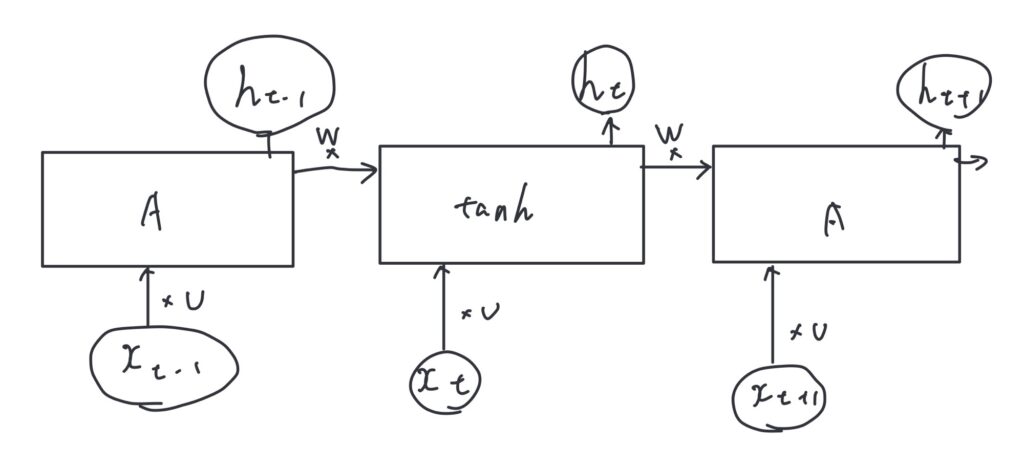
隠れ層の状態 $$h_t$$ は、前の時刻の隠れ層の状態$$h_{t-1}$$と現在の入力$$x_t$$を用いて計算されます。具体的には以下の式で表されます。
$$h_t = \tanh(W h_{t-1} + U x_{t} )$$
- 活性化関数(通常はハイパボリックタンジェント関数)$$\tanh$$
- ひとつ前の隠れ状態(h_{t-1})とtanhの間の重み行列$$W$$
- 入力xtとtanhとの間の重み行列$$U$$
RNNモデルを構築するためのmodel.pyの作成
今回実装していくモデルのアーキテクチャとして単語のIDを入力し、それをEmbedding層で分散表現に変換します。その後分散表現をSimpleRNN層に入力し、最後にDense層にsoftmax関数を組み込んで各クラスの確率を予測するモデルを作成します。
- インポート:
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Embedding, SimpleRNN必要なモジュールをインポートします。
- クラス定義:
class RNNModel:RNNModelクラスを定義します。
- 初期化メソッド:
def __init__(self, input_dim, output_dim, hidden_dim=100, emb_dim=300, embeddings=None, trainable=True):モデルのパラメータを初期化します。
- 入力層:
self.input = Input(shape=(None,), name='input')可変長のシーケンスを受け取る入力層を定義します。
- 埋め込み層:
if embeddings is None:
self.embedding = Embedding(input_dim=input_dim, output_dim=emb_dim, mask_zero=True, trainable=trainable, name='embedding')
else:
self.embedding = Embedding(input_dim=embeddings.shape[0], output_dim=embeddings.shape[1], mask_zero=True, trainable=trainable, weights=[embeddings], name='embedding')埋め込み層を定義します。事前学習済みの埋め込みがある場合はそれを使用します。
- RNN層:
self.rnn = SimpleRNN(units=hidden_dim, return_sequences=True, name='rnn')SimpleRNN層を定義します。
- 全結合層:
self.fc = Dense(units=output_dim, activation='softmax')出力層を定義します。
- モデル構築:
def build(self):
x = self.input
embedding = self.embedding(x)
output = self.rnn(embedding)
y = self.fc(output)
return Model(inputs=x, outputs=y)レイヤーを接続してモデルを構築します。
RNNのアーキテクチャをまとめると
# model.py
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Embedding, SimpleRNN
class RNNModel:
def __init__(self, input_dim, output_dim, hidden_dim=100, emb_dim=300, embeddings=None, trainable=True):
self.input = Input(shape=(None,), name='input')
# Embedding層の構築
if embeddings is None:
self.embedding = Embedding(input_dim=input_dim,
output_dim=emb_dim,
mask_zero=True,
trainable=trainable,
name='embedding')
else:
self.embedding = Embedding(input_dim=embeddings.shape[0],
output_dim=embeddings.shape[1],
mask_zero=True,
trainable=trainable,
weights=[embeddings],
name='embedding')
# SimpleRNN
self.rnn = SimpleRNN(units=hidden_dim,
name='rnn')
# Dense層の構築
self.fc = Dense(units=output_dim,
activation='softmax')
def build(self):
x = self.input
embedding = self.embedding(x)
output = self.rnn(embedding)
y = self.fc(output)
return Model(inputs=x, outputs=y)
このモデルは、まずEmbedding層で単語をベクトルに変換し、次にSimpleRNN層で時系列データを処理し、最後にDense層で出力を生成します。
予測を行うためのクラスを作成(inference.py)
今回もchapter7同様にamazonレビューをコーパスとして利用するため、評価を予測するためのクラスを作成していきます。
# inference.py
import numpy as np
from tensorflow.keras.preprocessing.sequence import pad_sequences
class InferenceAPI:
def __init__(self, model, vocab, preprocess):
self.model = model
self.vocab = vocab
self.preprocess = preprocess
def predict_from_texts(self, texts):
x = self.preprocess(texts)
x = self.vocab.texts_to_sequences(x)
return self.predict_from_sequences(x)
def predict_from_sequences(self, sequences):
sequences = pad_sequences(sequences, truncating='post')
y = self.model.predict(sequences)
return np.argmax(y, -1)- 初期化
- モデル、語彙、前処理関数を受け取って初期化します。
- テキストから予測
- テキストデータを前処理し、シーケンスに変換します。
- シーケンスを使って予測を行います。
- シーケンスから予測
- シーケンスをパディングして統一します。
- モデルを使って予測を行い、最も高い確率のクラスを返します。
このAPIは、テキストデータを入力として受け取り、モデルを使ってそのテキストのクラスを予測するために設計されています。
テキスト分類の評価方法
混同行列(Confusion Matrix)
混同行列は、モデルの予測結果を視覚的に評価するための表です。以下のように構成されます。
- 真陽性(TP)
- 偽陽性(FP)
- 真陰性(TN)
- 偽陰性(FN)
| 実際の陽性 (Positive) | 実際の陰性 (Negative) | |
|---|---|---|
| 予測の陽性 (Positive) | 真陽性 (TP) | 偽陽性 (FP) |
| 予測の陰性 (Negative) | 偽陰性 (FN) | 真陰性 (TN) |
正解率(Accuracy)
正解率は、全データのうち正しく分類されたデータの割合を示します。正解率を用いる意味は以下の通りです。
- 全体的なパフォーマンスの評価:正解率は、モデルが全体としてどれだけ正確に予測できているかを示します。これは、特にクラスの分布が均等な場合に有用です。
- 簡単で直感的:正解率は理解しやすく、一般的な評価指標として広く使われています。例えば、100個のデータのうち90個を正しく分類できた場合、正解率は90%となります。
- バランスの取れたデータセット:クラスの分布が均等である場合、正解率は有効な指標となります。しかし、クラスの不均衡がある場合には、他の指標(例えば適合率や再現率)と併用することが推奨されます。(例えばポジティブな意見が90%のデータセットを用いた場合、正答率は90%を超えないといけない。なぜなら、常にポジティブと予想していれば確実に90%の正答率になるから)
計算式は以下の通りです。
$$\text{Accuracy} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{FP} + \text{TN} + \text{FN}}$$
ここで、TPは真陽性、TNは真陰性、FPは偽陽性、FNは偽陰性を表します。
適合率(Precision)
適合率(Precision)は、テキスト分類モデルが「正」と予測したデータのうち、実際に「正」であったデータの割合を示します。具体的には、以下のような状況で重要です。
- 誤認識の影響が大きい場合:例えば、スパムメールフィルターでは、スパムと予測したメールが実際にスパムであることが重要です。誤って重要なメールをスパムと分類すると、大きな問題になります。
- 高い精度が求められる場合:医療診断など、誤診が許されない分野では、適合率が高いことが求められます。
計算式は以下の通りです。
$$\text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}}$$
再現率(Recall)
再現率は、実際に陽性であったデータのうち、モデルが正しく陽性と予測したデータの割合を示します。再現率を用いる意味は以下の通りです。
- 見逃しを減らす:再現率が高いモデルは、実際に「正」であるデータを見逃す(False Negative)が少ないことを意味します。例えば、病気の診断において、病気を見逃さないことが重要です。
- 重要なクラスの検出:特に、少数クラスの検出が重要な場合に再現率が重視されます。例えば、詐欺検出や異常検知など。
- バランスの取れた評価:適合率(Precision)と再現率のバランスを取るために、F1スコアなどと併用されることが多いです。
計算式は以下の通りです。
$$\text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}}$$
F1スコア
F1スコアは適合率と再現率の調和平均です。F1スコアを用いる意味は以下の通りです。
- バランスの取れた評価:適合率と再現率の両方を考慮するため、どちらか一方に偏らない評価が可能です。特に、クラスの不均衡がある場合に有効です。
- 総合的な性能評価:適合率が高くても再現率が低い、またはその逆の場合、F1スコアはそのバランスを反映します。これにより、モデルの総合的な性能を一つの数値で評価できます。
- 実用性:医療診断や詐欺検出など、誤検出や見逃しが重大な影響を与える分野で特に重要です。
以下の計算式で求められます。
$$\text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}$$
他クラス分類の時の評価方法
今回は二択の分類問題なので詳しく和解説しませんでしたが、テキスト分類を行う際に多クラスに分類する問題もあるかと思います。その際にも上記の5つの方法を使うことができます。
それぞれの評価値を計算する際にはマクロ平均とマイクロ平均という考え方が使われます。
マクロ平均(Macro Average)
マクロ平均は、各クラスの評価指標(例えば、精度や再現率)の平均を取る方法です。各クラスの評価指標を計算し、それらの平均を求めます。この方法は、クラス間のバランスが取れていない場合に有効です。なぜなら、各クラスが同等に扱われるため、少数クラスの性能も反映されるからです。
例:
クラスA、クラスB、クラスCの3つのクラスがあるとします。それぞれのクラスの精度が以下の通りだった場合:
- クラスAの精度:0.9
- クラスBの精度:0.8
- クラスCの精度:0.7
マクロ平均の精度は以下のように計算されます:
$$Macro Precision=30.9+0.8+0.7=0.8$$
マイクロ平均(Micro Average)
マイクロ平均は、全てのクラスのTP(True Positive)、FP(False Positive)、FN(False Negative)を合計してから評価指標を計算する方法です。この方法は、クラス間のバランスが取れている場合に有効です。全体のパフォーマンスを一つの大きなクラスとして評価するため、データの偏りが少ない場合に適しています。
例:
クラスA、クラスB、クラスCの3つのクラスがあり、それぞれのTP、FP、FNが以下の通りだった場合:
- クラスA: TP = 50, FP = 10, FN = 5
- クラスB: TP = 40, FP = 20, FN = 10
- クラスC: TP = 30, FP = 15, FN = 20
全クラスのTP、FP、FNを合計します:
- 総TP = 50 + 40 + 30 = 120
- 総FP = 10 + 20 + 15 = 45
- 総FN = 5 + 10 + 20 = 35
マイクロ平均の精度は以下のように計算されます:
$$\text{Micro Precision} = \frac{120}{120 + 45} \approx 0.727$$
このように、マクロ平均とマイクロ平均はそれぞれ異なる視点からモデルの性能を評価するために使用されます。どちらを使用するかは、データの特性や評価の目的によります。
RNNモデルの学習と評価を行うコード(train.py)
最後にこれまでに記述した内容に基づいてモデルを学習させ、そのモデルの評価を行いたいと思います。
# train.py
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.metrics import f1_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
from preprocessing import preprocess_dataset, build_vocablary
from inference import InferenceAPI
from utils import load_dataset
from model import RNNModel
def main():
# ハイパラメータの設定
batch_size = 128
epochs = 100
maxlen = 300
model_path = 'models/rnn_model.keras'
num_words = 40000
num_label = 2
# データセットの読み込み
x, y = load_dataset('/content/drive/MyDrive/自然言語処理編/chapter9/dataset.csv')
# データセットの前処理
x = preprocess_dataset(x)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
vocab = build_vocablary(x_train, num_words)
x_train = vocab.texts_to_sequences(x_train)
x_train = pad_sequences(x_train, maxlen=maxlen, truncating='post')
# モデルの構築
model = RNNModel(num_words, num_label, embeddings=None).build()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# コールバックの用意
callbacks = [EarlyStopping(patience=3), ModelCheckpoint(model_path, save_best_only=True)]
# モデルの学習
history = model.fit(x=x_train, y=y_train, batch_size=batch_size, epochs=epochs, validation_split=0.2, callbacks=callbacks, shuffle=True)
# 予測
model = load_model(model_path)
api = InferenceAPI(model, vocab, preprocess_dataset)
y_pred = api.predict_from_texts(x_test)
print('precition: {:.4f}'.format(precision_score(y_test, y_pred, average='binary')))
print('recall: {:.4f}'.format(recall_score(y_test, y_pred, average='binary')))
print('f1 score: {:.4f}'.format(f1_score(y_test, y_pred, average='binary')))
if __name__ == '__main__':
main()このコードを正しく動かすためには下記のファイルが同じフォルダ内にある必要があります。
model.py
# model.py
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Embedding, SimpleRNN
class RNNModel:
def __init__(self, input_dim, output_dim, hidden_dim=100, emb_dim=300, embeddings=None, trainable=True):
self.input = Input(shape=(None,), name='input')
# Embedding層の構築
if embeddings is None:
self.embedding = Embedding(input_dim=input_dim,
output_dim=emb_dim,
mask_zero=True,
trainable=trainable,
name='embedding')
else:
self.embedding = Embedding(input_dim=embeddings.shape[0],
output_dim=embeddings.shape[1],
mask_zero=True,
trainable=trainable,
weights=[embeddings],
name='embedding')
# SimpleRNN
self.rnn = SimpleRNN(units=hidden_dim,
name='rnn')
# Dense層の構築
self.fc = Dense(units=output_dim,
activation='softmax')
def build(self):
x = self.input
embedding = self.embedding(x)
output = self.rnn(embedding)
y = self.fc(output)
return Model(inputs=x, outputs=y)inference.py
# inference.py
import numpy as np
from tensorflow.keras.preprocessing.sequence import pad_sequences
class InferenceAPI:
def __init__(self, model, vocab, preprocess):
self.model = model
self.vocab = vocab
self.preprocess = preprocess
def predict_from_texts(self, texts):
x = self.preprocess(texts)
x = self.vocab.texts_to_sequences(x)
return self.predict_from_sequences(x)
def predict_from_sequences(self, sequences):
sequences = pad_sequences(sequences, truncating='post')
y = self.model.predict(sequences)
return np.argmax(y, -1)utils.py
import pandas as pd
import string
def filter_by_ascii_rate(text, threshold=0.9):
ascii_letters = set(string.printable)
if isinstance(text, str):
rate = sum(c in ascii_letters for c in text) / len(text)
return rate <= threshold
else:
return False
def load_dataset(filename, n=5722, state=6):
df = pd.read_csv(filename, sep=',')
df['Label'] = df['Label'].astype(int)
# Converts multi-class to binary-class.
mapping = {1: 0, 2: 0, 4: 1, 5: 1}
df = df[df['Label'] != 3]
df['Label'] = df['Label'].map(mapping)
# extracts Japanese texts.
is_jp = df['Content'].apply(filter_by_ascii_rate)
df = df[is_jp]
# sampling.
df = df.sample(frac=1, random_state=state) # shuffle
grouped = df.groupby('Label')
df = grouped.head(n=n)
return df['Content'].values, df['Label'].valuespreprocessing.py
#preprocessing.py
from bs4 import BeautifulSoup
from janome.tokenizer import Tokenizer
import tensorflow as tf
t = Tokenizer(wakati=True)
def build_vocablary(texts, num_words):
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=num_words, oov_token='<UNK>')
tokenizer.fit_on_texts(texts)
return tokenizer
def tokenize(text):
return t.tokenize(text)
def clean_html(html, strip=False):
soup = BeautifulSoup(html, 'html.parser')
text = soup.get_text(strip=strip)
return text
def preprocess_dataset(texts):
texts = [clean_html(text) for text in texts]
texts = [' '.join(tokenize(text)) for text in texts]
return textsデータセットの読み込みの部分はデータを置いた場所を指定してください。
このコードを実行すると下記のような予測の精度を見ることができます。
# results
precition: 0.8219
recall: 0.7007
f1 score: 0.7564RNNモデルを学習した感想
今回はRNNモデルの学習に挑戦してみて一気に難易度がまた難しくなったと感じました。
しかし、RNNの仕組みを学ぶことでより自然言語処理に対する理解が深まりました。次回はRNNの改良版であるLSTMモデルの学習を行っていきたいと思います。
この記事は下記の書籍を参考にしています。


コメント